Encoding and Python: The UnicodeDecodeError exception
UnicodeDecodeError: 'ascii' codec can't decode something in position somewhere: ordinal not in range(128)
It all started with "ASCII" (it's a encoding, things will get more clear later) which was proposed in 1962. The idea was to represent english text by relating them to "decimal numbers" (read bytes and ultimately bits).
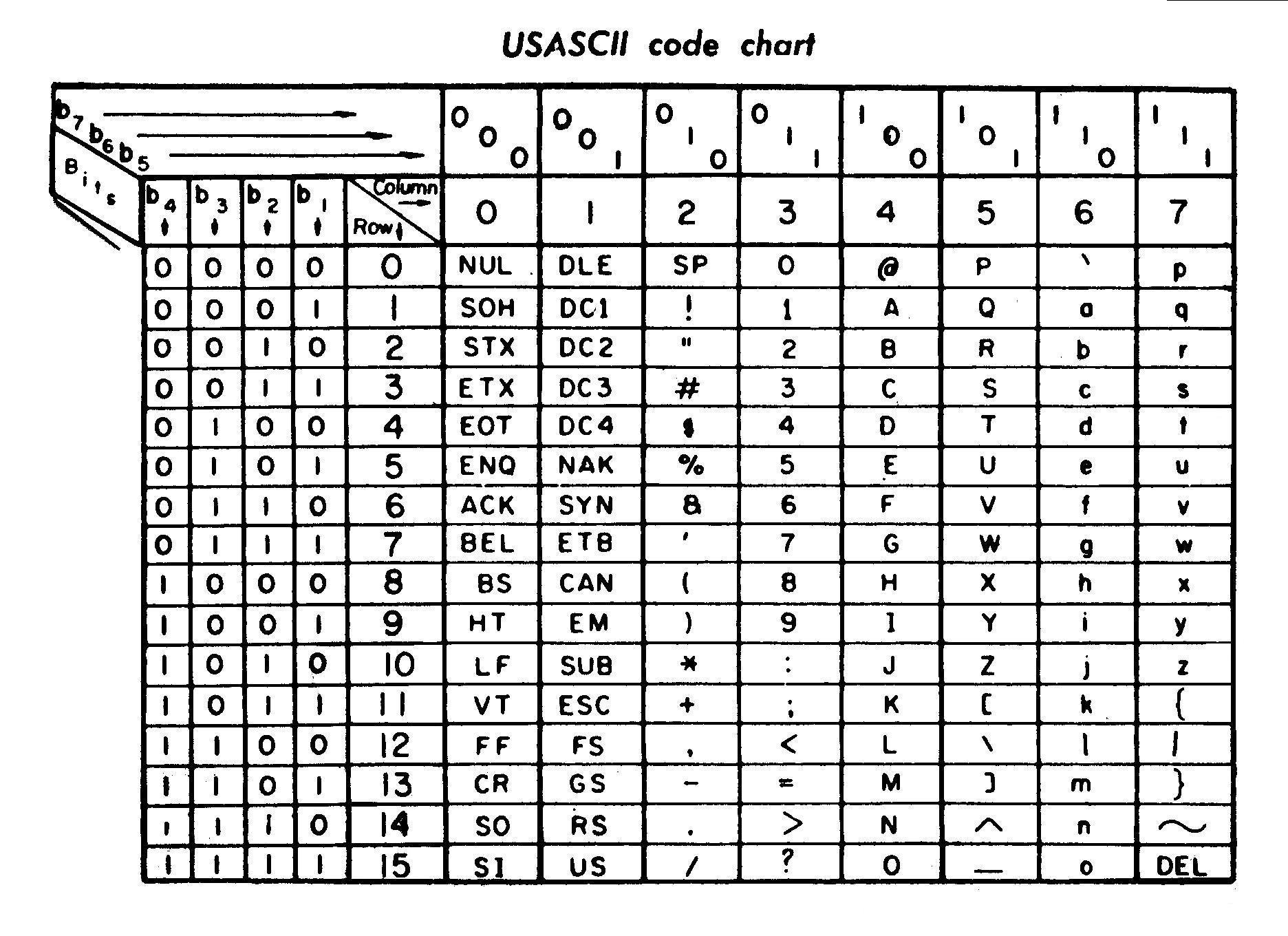
So, "1000001" (binary number, or 65 in decimal) in ASCII encoding corresponds to "A". This "A" is just a "glyph" (A mark that corresponds to A).
Sadly, this way of representing was not sufficient to represent all characters/symbols in the world. In the good old world, when people couldn't find the characters they wanted, they started creating their own encodings. Hence, encodings like latin, utf-8, utf-32 came in. This was good until a chinese guy just wanted to just write chinese (read any chinese dialect) and not combine both chinese and latin. Hence, there was a problem to represent all possible characters in one string (as not all characters might lie in one encoding).
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 13144: ordinal not in range(128)
Now, lets understand what this error actual means.
- It's a exception UnicodeDecodeError that is not caught.
- It says that while using "ascii" codec (read encoding), it couldn't decode the byte "0xe2" which is present at 13144.
Lets start with understand what unicode is. Unicode is a way to represent different glyphs using strings. It tries to include all characters possible. For ex, a "halfwidth katakana middledot" which has gylph (http://www.fileformat.info/info/unicode/char/ff65/index.htm) can be represented by a string like \uff65. This way, Unicode tries to represent all the characters and symbols possible in all languages.
So, 'ascii' is a encoding. Old-style str instances use a single 8-bit byte to represent each character of the string using its ASCII code. Python tried to represent a character with 'ascii' encoding but it failed as it didn't exist. But, why the hell ascii? Isn't it old? That's because, python 2's default encoding is "ascii".
➜ 0 /home/shadyabhi [ 8:19PM] % locale
LANG=en_US.UTF-8
LC_CTYPE=en_US.UTF-8
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
➜ 0 /home/shadyabhi [ 8:19PM] % python2 -c 'exec("import sys; print sys.getdefaultencoding()")'
ascii
➜ 0 /home/shadyabhi [ 8:19PM] %
If you want to change default encoding to utf-8 in python, you can do a hack:
import sys
# Set default encoding to 'UTF-8' instead of 'ascii'
# http://stackoverflow.com/questions/11741574/how-to-set-the-default-encoding-to-utf-8-in-python
# Bad things might happen though
reload(sys)
sys.setdefaultencoding("UTF8")
This part is fixed in python3 by making "str" as a Unicode object where "str" object actually manages the sequence of Unicode code-points.
Now that we understand the exception, to fix it, you need to "decode" the string in the proper encoding that actually understands it. The "decoding" will make sure that the particular character which caused the exception earlier is actually a known character now. To encode/decode strings, python has two functions:
- s.decode("ascii"): converts str object to unicode object
- u.encode("ascii"): converts unicode object to str object
>>> u'・'
u'\uff65'
>>> u'・'.encode('utf-8')
'\xef\xbd\xa5'
>>> '\xef\xbd\xa5'.decode('utf-8')
u'\uff65'
>>> print '\xef\xbd\xa5'.decode('utf-8')
・
>>> '\xef\xbd\xa5'.decode('ascii')
Traceback (most recent call last):
File "<input>", line 1, in
UnicodeDecodeError: 'ascii' codec can't decode byte 0xef in position 0: ordinal not in range(128)
>>>
I faced above error when I was trying to parse webpages and get text out of it using "html2text" module. As python 2's default encoding is "ascii", it's stupid to assume that all the websites can be represented in "ascii" encoding.
How do we guess the encoding of text then?We can't.Some encodings have BOM and they can be used to detect text encoding while for others, there is simply no way. Well, there is a module named chardet that you can use to guess the encoding though. I repeat, there is no reliable way to guess the encoding. While parsing web-pages, there is mostly a header like:
Content-Type: text/html; charset=utf-8
or the webpage may start with:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
which can be used to get the encoding related information. Wait, but how do we read the encoded text without knowing the encoding? Luckily, the name of all encodings can be represented in that basic "ascii" encoding so that's not a problem.
This information can then be used to convert it to Unicode in python
page_content.decode(encoding_in_header)
Once that is done, you can do whatever you want with it. If you need to save to disk, you need encode it back though.
If the webpage is bitchy and gives a false header, you get a exception UnicodeDecodeError if you're using "strict" option, which is default. If you still want to decode anyway, use "ignore" or "replace".
page_content.decode(encoding_in_header, 'ignore')
It's a good practice to decode string to Unicode as soon as we receive it from external source and operate on it. When we're done with it and want to give back or store somewhere, encode it again. Then why is it not done in Python 2? Because, not all core parts of python operate on Unicode. This is fixed in Python 3.
I hope this gives a little idea of what's this Unicode and how to handle different encodings in your code.
Further Reading: